技术视角下的「北京记忆」:二十一年数字化积淀如何重构城市历史知识服务
2015年,我第一次接触首都图书馆的数字化项目。彼时地方文献的碎片化存储几乎是行业通病,而当我翻开「北京记忆」最早的版本时,结构化程度远超预期。2024年4月24日,新版「北京记忆」正式上线,我花了三天时间完整梳理其技术架构,这篇记录即为阶段性复盘。
底层数据资产:近百年地方文献的系统性整合
新版平台的核心语料源自首都图书馆近百年积淀的地方文献。系统整合地方文献约2万种、特色专题14个、音频2900余条。新增古籍和现代文献共计11万页的精细标引数据、4670分钟视频字幕转录。这组数字背后是持续二十一年的数据清洗与元数据规范化工程。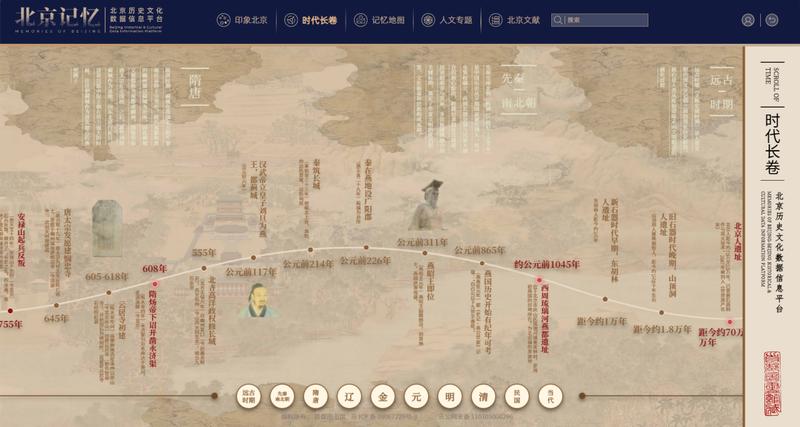
3500余件具有重要史料价值的拓片、近800张戏报等珍贵文献完成精细化加工后在全文内容中实现了单字及词语级别的精准检索。这意味着检索「康熙」不再只是模糊匹配,而是定位到具体拓片的每一处刻痕。
时空GIS引擎:历史舆图与当代坐标的精准耦合
平台利用时空GIS技术将17张北京历史舆图与现代地理坐标体系精准匹配,实现图中每一处地点与唯一经纬度坐标对应。这项技术突破使「山河湖泊、城池宫阙、坊巷胡同等十余类地理标识」可以在当下地图上直接定位与历史溯源。从技术实现角度,坐标映射精度直接决定后续空间分析的可用性。
叠加分析能力是本次升级的核心亮点。民国《北京明细全图》等7张历史舆图与现代城市空间图层的叠压,使城市空间的古今变迁得到清晰可视化呈现。这为数字人文研究提供了可量化的空间分析基础。
双入口架构:专业用户与普通读者的需求分层
平台在网页端搭建「打开记忆」与「北京文献」双入口,分别对应不同用户群体的使用场景。「打开记忆」下设「印象北京」「时代长卷」「记忆地图」「人文专题」四大模块,面向社会公众,以形象化方式呈现内容体系。「北京文献」则提供直达入口,为北京历史、地理、文化、数字人文等研究提供基于原始文献的权威支撑。
五大资源门类——图书资源、图像资源、报刊资源、影音资源、特种文献——构成完整的城市记忆数字基座。各模块所涉实体均与「北京文献」中的多模态资源深度关联,从任一模块切入均可层层链接进入全库文献资源。
文献阅读功能集:个体知识建构的工具链
文献阅读界面集成了书内检索、全库检索、图文对照、繁简转换、字典查阅、个人笔记、收藏与分享等功能。这套工具链的设计逻辑指向个体知识建构场景:检索定位→对照阅读→笔记沉淀→分享交流。功能粒度划分清晰,用户可以根据实际需求选择组合使用。
从技术评估角度,新版「北京记忆」在数据结构化程度、空间分析能力、资源关联深度三个维度实现了显著提升。二十一年的建设积累正在通过这版升级释放更深层的知识服务价值。